Overview
This tutorial walks through how an application can leverage CDP architecture to create fast, lightweight Stellar Ledger Metada data pipelines using a few select packages from the Stellar Go Repo github.com/stellar/go-stellar-sdk collectively known as the 'Ingestion' SDK:
The Ingestion SDK packages
github.com/stellar/go-stellar-sdk/amountutility package to convert prices from network transaction operations to stringgithub.com/stellar/go-stellar-sdk/historyarchivegithub.com/stellar/go-stellar-sdk/support/datastoregithub.com/stellar/go-stellar-sdk/support/storageutility package with convenient wrappers for accessing history archives, and avoid low-level http aspectsgithub.com/stellar/go-stellar-sdk/ingestprovides parsing functionality over the network ledger metadata, converts to more developer-centricLedgerTransactionmodelgithub.com/stellar/go-stellar-sdk/networkprovides convenient pre-configured settings for Testnet and Mainnet networksgithub.com/stellar/go-stellar-sdk/xdra complete Golang binding to the Stellar network data model
Ingestion Project Setup
Project Requirements
To use this example CDP pipeline for live Stellar network transaction data, you'll need:
- A developer workstation with Go programming language runtime installed
- An IDE to edit Go code, VSCode is good if one is needed
- A newly initialized, empty Go project folder.
mkdir pipeline; cd pipeline; go mod init example/pipeline - Some familiarity to the Stellar Ledger Metadata model. It is defined in an IDL format expressed in XDR encoding.
- Docker
- Google Cloud Platform account:
- a bucket created in Google Cloud Storage(GCS)
- GCP credentials in workstation environment
Our example application is only interested in a small subset of the overall network data model related to asset transfers triggered by Payment operation and defines its own derived data model as the goal of exercise:
- Example
::AppPayment
Timestamp: uint
BuyerAccountId: string
SellerAccountId: string
AssetCode: string
Amount: string
}
The example application will perform both of CDP pipelines. A minimum of two pipelines are required for a complete end to end CDP architecture.
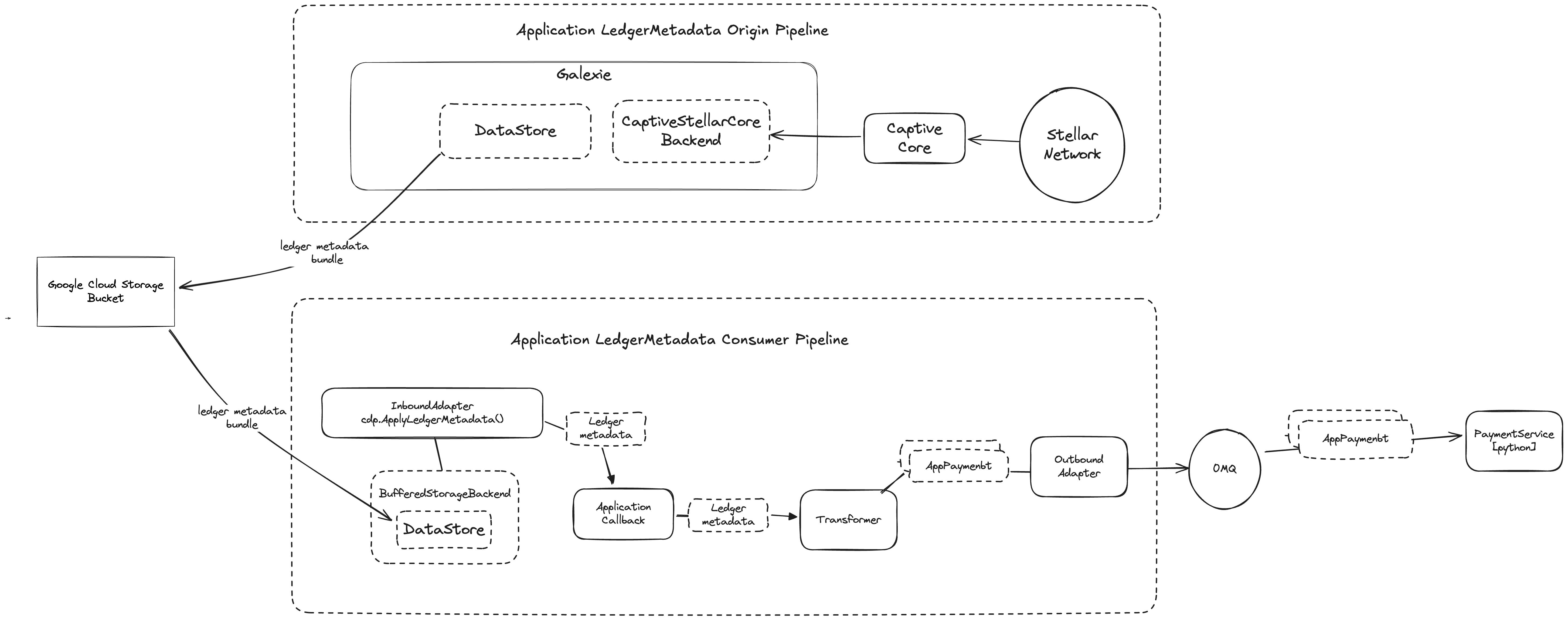
Ledger Metadata Export Pipeline
This pipeline needs to be initiated first, it is responsible for exporting Stellar Ledger Metadata as files to a CDP Datastore.
Determine the Datastore
The Datastore in CDP is an interface, allowing for multiple implementations which represent different physical storage layers that can be 'plugged in' to export and consumer pipelines. Stellar provides the [GCS Datastore] as the first Datastore implementation, and this example chooses to use this existing implementation.
There will be open source contributions for implementations on other storage layers to choose from as CDP grows. If you can't find an implementation for a storage layer you would like to use, it is also possible to develop your own Datastore implementation, which is beyond scope of this example, as it entails a separate learning exercise of its own, coming soon!
Exporting network metadata to Datastore
Use Galexie, a new CDP command line program for exporting network metadata to datastores.
-
Follow the Galexie setup steps in Galexie User Guide, to configure specifics of GCS bucket and target network.
-
Follow the Galexie docker runtime instructions to start the export.
- For one time export of historical bounded range of ledgers, use
append --start <from_ledger> --end <to_ledger> - For a continuous export of prior ledgers and all new ledgers generated on network, use
append --start <from_ledger>.
- For one time export of historical bounded range of ledgers, use
Ledger Metadata Consumer Pipeline
A consumer pipeline retrieves files from the GCS bucket and uses them as the origin of Ledger Metadata in a data processing pipeline. There can be many separate consumer pipelines all accessing the same Datastore at stame time. Each consumer pipeline will typically perform three distinct stream processor roles:
Inbound Adapter
The 'source of origin' for the ledger metadata in a pipeline. This processor retrieves LedgerCloseMeta files from the GCS Datastore, extracts the LedgerCloseMeta for each Ledger and publishes it onto the messaging pipeline.
The go sdk provides consumer helper function ApplyLedgerMetadata for automated, performant, buffered retrieval of files from the remote datastore, application code can leverage this to acquire pure LedgerCloseMeta data from a callback function.
Transformer
Subscribes on the pipeline to receive LedgerCloseMeta. Uses the Go SDK package github.com/stellar/go-stellar-sdk/xdr to parse the ledger meta data model for payment operations and convert those into a new instance of application data model AppPayment instances. Publishes AppPayment to the pipeline.
Outbound Adapter
Acts as the termination of the pipeline, it subscribes to receive ApplicationPayment and publishes the data off the pipeline and to an external data store, a ZeroMQ Publisher Socket, which is essentially a message broker.
Summary
Refer to Ingestion Pipeline Sample Application for complete consumer code example, demonstrating a live, streaming pipeline against the Stellar network, processing each new ledger's metadata as it is closed on the network.